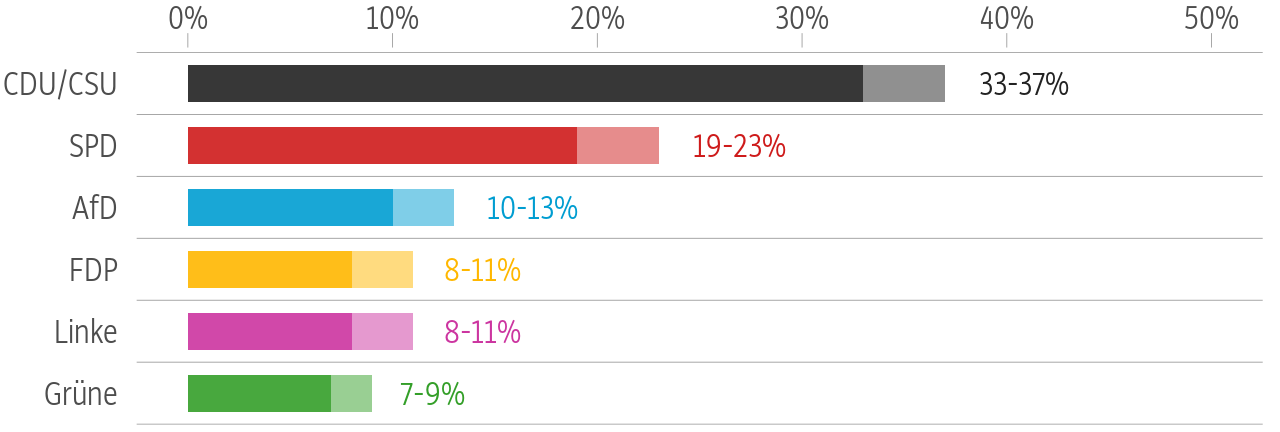
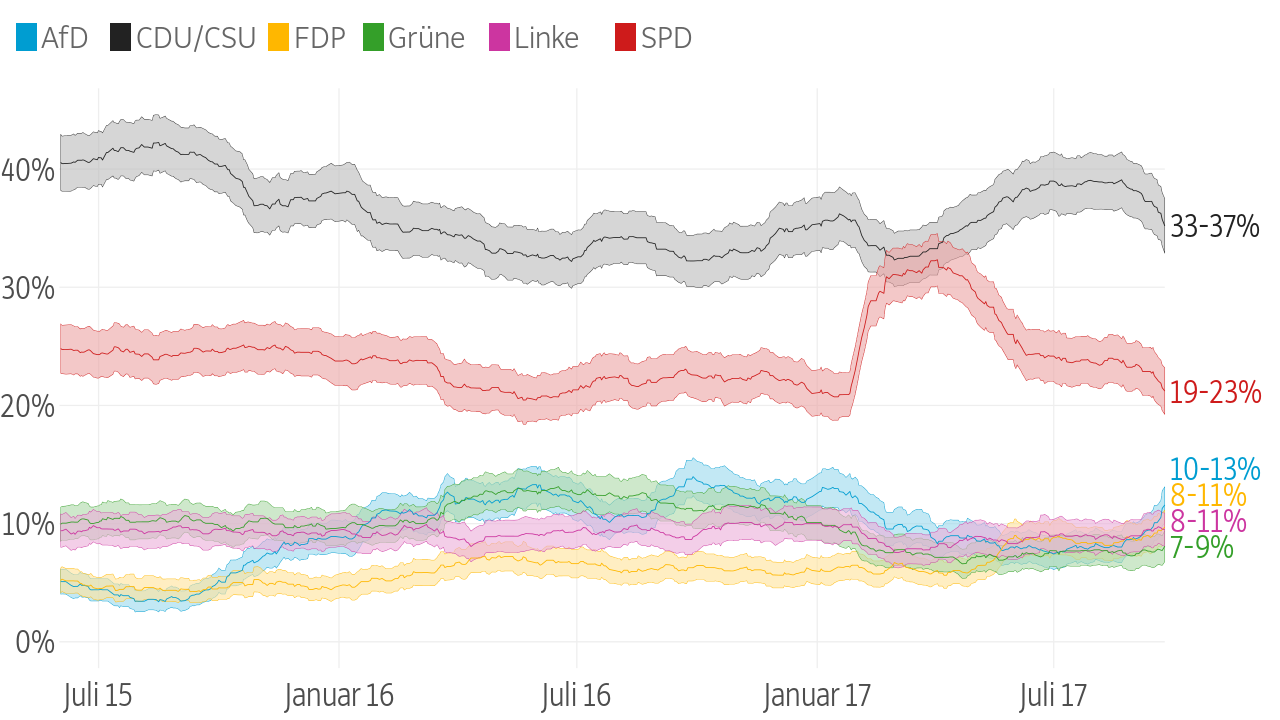
Für die aktuelle Ausgabe der SZ haben meine Kollegin Julia Kraus und ich eine Grafik produziert, die zeigt wer von geplanten Steuerentlastungen einer möglichen neuen Großen Koalition profitieren würde. Da ich danach gefragt wurde, hier ein paar Dinge zu unserer Vorgehensweise.
Grundlage der Simulation ist das Papier, in dem CDU, CSU und SPD die Ergebnisse ihrer Sondierungsgespräche festgehalten haben. Wir haben das Dokument auf SZ.de veröffentlicht (PDF). Ab Seite 15 gibt es ein Kapitel zu Steuern und Finanzen, das zwar relativ knapp gehalten ist, aus dem sich die wesentlichen Punkte aber dennoch ziemlich deutlich herauslesen lassen.
- 90 Prozent der Steuerzahler sollen vom Soli befreit werden. Das sind alle Haushalte, die weniger als etwa 70.000 Euro brutto im Jahr verdienen.
- Die Beiträge der Krankenkasse werden künftig wieder von Arbeitgebern und Arbeitnehmern gleichmäßig bezahlt.
- Die Beiträge zur Arbeitslosenversicherung sinken um 0,3 Prozentpunkte.
- Kindergeld und Kinderfreibetrag werden erhöht.
Wissenschaftler der beiden Institute ZEW und IZA haben für uns die Auswirkungen dieser Maßnahmen berechnet. Dafür haben sie zwei Datengrundlagen verwendet: einmal einen Datensatz der Finanzverwaltung, der anonymisierte Steuererklärungen erhält. Darin sind ca 40 Parameter enthalten, die für die Steuer relevant sind – Kinderzahl, Freibeträge, Steuerklasse etc. Außerdem Daten aus dem Sozio-ökonomischen Panel, einer großen Bevölkerungsbefragung, bei der die Teilnehmer Angaben etwa zu ihren Einkommensverhältnissen machen. Beide Datensätze haben gewisse Schwächen, in der Kombination erlauben sie es den Forschern aber Cross-Checks zu machen und zu sehr validen Ergebnissen zu kommen.
Für jeden Einträg in diesen Datensätzen können die Forscher nun berechnen, was die von der Groko geplanten Änderungen an den Formeln für Steuern und Sozialbeiträge ändern würden, und daraus die gesamte Entlastung für jeden Haushalt berechnen. Daraus haben wir mehrere Auszüge veröffentlicht: die durchschnittliche Entlastung für zehn verschiedene Einkommensgruppen und für verschiedene typische Beispiel-Haushalte. Und das, was die Grafik oben zeigt: die jeweilige Entlastung für etwa 15.000 repräsentativ ausgewählte Einzelhaushalte.
Auf diese Visualisierung bin ich ein bisschen stolz. Denn das deutsche Steuersystem ist mit all seinen Ausnahmen und Sonderregelungen hochkomplex und hochindividuell. Kaum ein Steuerfall gleicht dem anderen. Daher zeigen wir nicht nur Mittel- und Beispielwerte – sondern in einer Grafik mit 15.000 Einzelpunkten das ganze Spektrum.
Hier noch eine Variante der Grafik, die die relative Entlastung in Prozent des Einkommens zeigt:
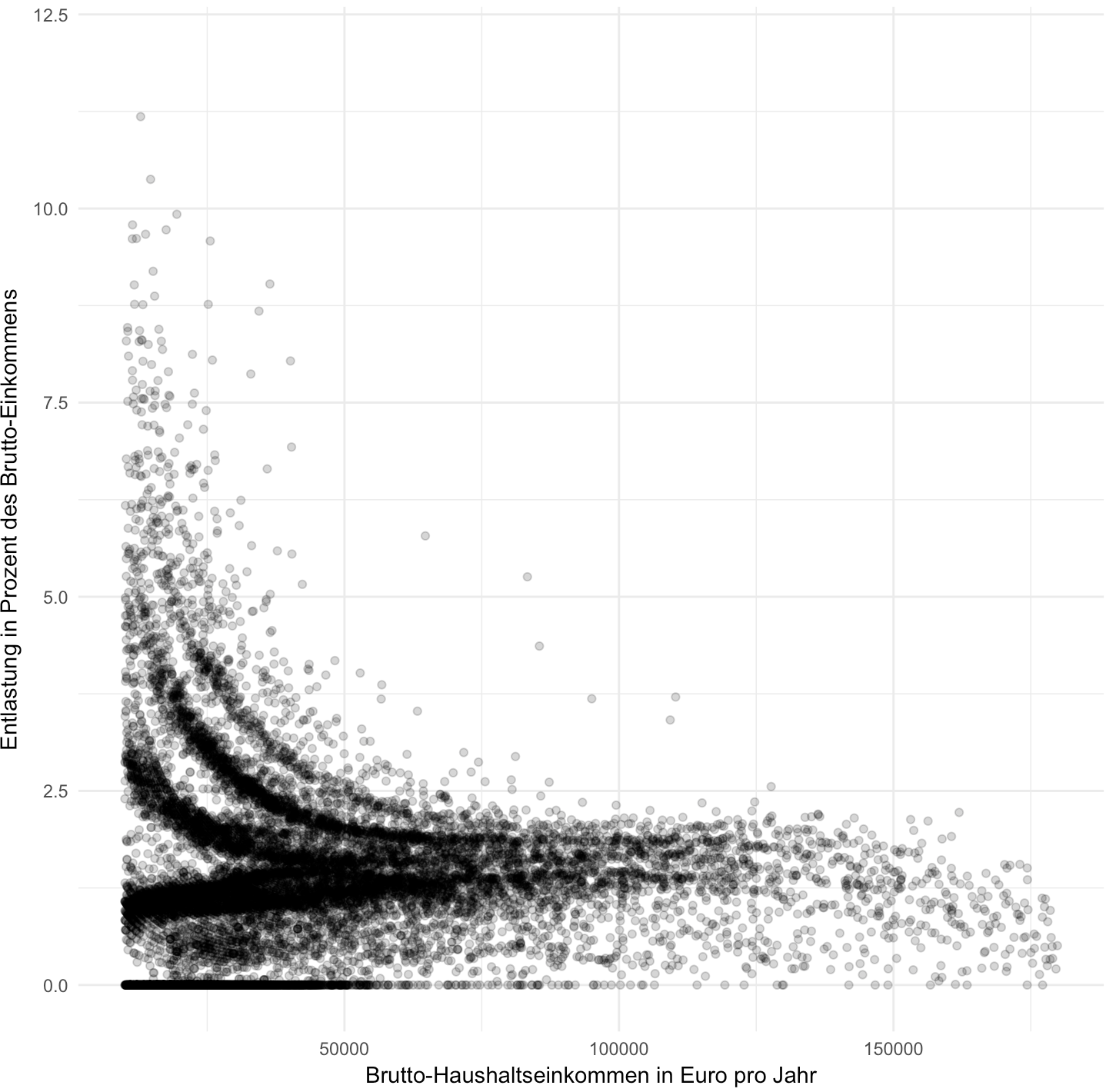
Das Projekt ist inspiriert von dieser Visualisierung der New York Times.
Fragen? Anmerkungen? Gerne hier in die Kommentare oder in der Diskussion auf Facebook und Twitter.