Yeah! Seit einiger Zeit versuche ich mittels Codeacademy, das Programmieren mit Python zu lernen. Gerade habe ich zum ersten Mal eine eigene Datenanalyse in Python gemacht.
Es geht um meinen Newsletter für den Blog hier. Der funktioniert so, dass er jeden Tag zu einer bestimmten Uhrzeit prüft, ob ein neuer Beitrag auf cendt.de vorhanden ist. Wenn ja, schickt er eine Mail an alle Abonnenten. Diese Uhrzeit ist jeden Tag gleich, lässt sich aber frei wählen.
Meine Frage war nun: Wann ist die ideale Zeit für den Newsletter-Versand? Ziel ist dabei, die Leser möglichst schnell zu informieren. Die Wartezeit zwischen Erscheinen des neuen Beitrags und Versenden des Newsletters soll also minimal sein.
Zuerst habe ich mir angesehen, zu welchen Zeiten ich hier so poste. Dazu habe ich aus WordPress die Daten zu allen 128 bisher veröffentlichten Beiträgen exportiert. Das war wesentlich schwieriger als gedacht: WordPress stellt nur einen XML-Export zur Verfügung (es gibt eine Menge Plug-Ins, die angeblich CSV-Export ermöglichen, bei mir hat aber kein einziges funktioniert). Dabei erhält man eine Datei, die Metadaten UND Inhalt zu allen Beiträgen enthält. Die Zeile, die mich dabei jeweils interessiert, sieht so aus:
2015-02-13 07:39:58
Es war erstmal ein ziemliches Gefrickel, nur diese Zeilen au den 8000 Zeilen XLM-Code rauszufiltern – Notepad++ hat dazu aber ein paar gute Funktionen. Mit Calc, dem Excel-Klon von OpenOffice (ich weiß, alle echten Statistiker hören jetzt auf zu lesen), habe ich daraus jeweils die Stunde ausgelesen und durchgezählt. Es entsteht folgende Verteilung:
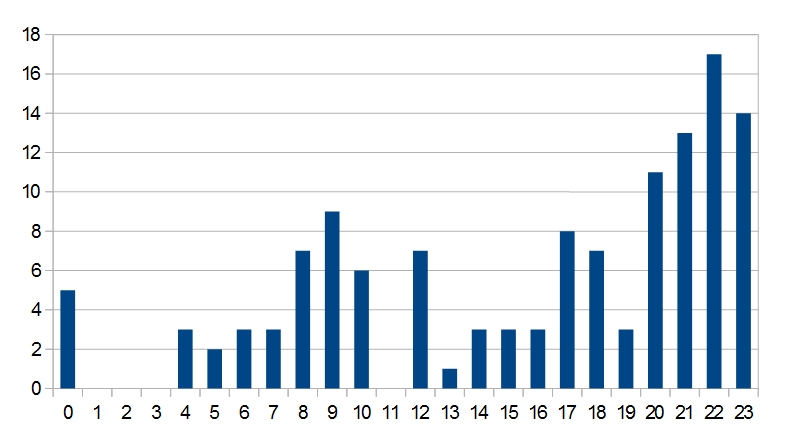
Blogposts nach Uhrzeit. Jeweils abgerundet auf volle Stunden. 22 bedeutet also 22:00 bis 22:59 Uhr.
Ich blogge also vor allem abends, mit einem Peak zwischen 22 und 23 Uhr. Morgens zwischen acht und elf gibt es eine zweite Hochphase. Noch nie gebloggt habe ich demnach zwischen ein und 4 Uhr nachts und zwischen elf und zwölf Uhr vormittags.
Intuitiv würde man jetzt sagen, dass ein Newsletter so um null oder ein Uhr wahrscheinlich am meisten Sinn macht. Ich wollte es aber genau wissen und habe ein Skript geschrieben, um die ideale Zeit zu bestimmen. Das bekommt als Input die Stundendaten aller bisherigen Posts:
[4,21,21,22,22,22,23,23,23,23,23,23,23,23,23,23,22,23,19,21,10,17,22,20,20,23,21,0,9,12,12,8,15,12,5,21,20,22,12,20,20,19,0,15,18,21,4,17,12,9,9,21,18,17,9,22,14,0,21,9,15,18,17,7,8,21,16,22,21,10,14,20,22,14,21,23,8,20,5,8,21,22,22,18,22,17,20,0,8,23,22,10,19,8,10,18,22,17,22,17,18,22,9,18,7,8,9,9,4,6,6,6,20,12,21,12,10,10,20,0,16,17,22,20,9,16,13,7]
Dann fängt es an, 24 Möglichkeiten für den Versand-Zeitpunkt durchzuspielen (jede volle Stunde). Für jede Möglichkeit rechnet mein Programm die Verzögerung gegenüber den Posts aus und merkt sich, welcher Zeitpunkt der beste war. So sieht der Code aus:
postdata = [4,21,21,22,22,22,23,23,23,23,23,23,23,23,23,23,22,23,19,21,10,17,22,20,20,23,21,0,9,12,12,8,15,12,5,21,20,22,12,20,20,19,0,15,18,21,4,17,12,9,9,21,18,17,9,22,14,0,21,9,15,18,17,7,8,21,16,22,21,10,14,20,22,14,21,23,8,20,5,8,21,22,22,18,22,17,20,0,8,23,22,10,19,8,10,18,22,17,22,17,18,22,9,18,7,8,9,9,4,6,6,6,20,12,21,12,10,10,20,0,16,17,22,20,9,16,13,7]
postcount = len(postdata)
def delaycalc(testtime):
delay = 0
for i in range(postcount):
dist = testtime - postdata[i]
if dist>=0:
delay = delay + dist
else:
delay = delay + 24 + dist
return delay
totaldelay = delaycalc(0)
newstime = 0
for testtime in range (1,23):
testdelay = delaycalc(testtime)
if testdelay < totaldelay:
totaldelay = testdelay
newstime = testtime
else:
totaldelay = totaldelay
avrgdelay = totaldelay/postcount
print ("Ideale Zeit: ",newstime,". Gesamtverzoegerung: ",totaldelay,". Im Durschnitt: ",avrgdelay)
Und so das Ergebnis im Compiler:
>>>
Ideale Zeit: 0 . Gesamtverzoegerung: 954 . Im Durschnitt: 7.453125
>>>
Tatsächlich sollte und werde ich meinen Newsletter zukünftig um Mitternacht verschicken. Im Durchschnitt geht der dann 7,5 Stunden nach Erscheinen des Beitrags raus.
Da ich mit dem Professor für Optimierung an meiner Uni nicht klar gekommen bin, habe ich das leider nie gelernt und weiß nicht, ob mein einfaches Vergleichen der Verzögerungs-Summen mathematisch die beste Lösung ist. Wenn da jemand eine bessere Idee hat, gerne melden. Mir ging es in erster Linie ums Programmieren.